Научные и прикладные результаты лаборатории 13
Основные результаты, полученные в ходе выполнения научно-исследовательских работ за 2024 год
- За счет оптимизации вычислительного конвейера по реализации конечно-разностной схемы МакКормака (для численного решения нелинейной системы уравнений мелкой воды) на предложенной ранее архитектуре специализированного вычислителя на базе вентильной матрицы программируемой пользователем (Field Programmable Gates Array – FPGA) удалось добиться проведения расчетов распространения волны цунами на сетке в разрешением 1 географическая минута, что позволило промоделировать распространение волны цунами через весь Тихий океан на базе персонального компьютера. Ранее такие расчеты проводились только с использованием суперкомпьютерных ресурсов.
- Показано, что использование спецпроцессора Xilinx Virtex-7 VC709 в составе стандартного ПК позволяет произвести расчет распространения волны цунами на сетке 9601х6781 узлов 36000 шагов по времени с интервалом 3 сек (то есть 30 часов распространения волны) за 22,5 минуты.
- Практическая ценность работы по разработке программно-аппаратного решения на базе FPGA в составе стандартного ПК состоит в возможности моделирования распространения (системы уравнений мелкой воды) на базе стандартного ПК без доступа к высокопроизводительным серверам и кластерам, что актуально для обеспечения беспрерывного функционирования систем предупреждения в прибрежных зонах, где в случае опасности часто случаются перебои с электричеством и доступам к высокоскоростным линиям связи.
- Проведено исследование зависимости распределения максимальных высот волны цунами в акватории Тихого океана от расположения модельного источника у побережья Южной Америки которое показало что положение источника существенно влияет на расположение максимальных высот волны в северо-западной части Тихого океана. Так, в случае источника цунами в южной части зоны субдукции наибольшей опасности подвергается побережье Алеутских островов, в то время как побережье Камчатки, Курильских островов и Сахалина не находится в зоне опасности. В случае расположения источника в северной части зоны субдукции основная энергия волны рассеивается в Тихом океане.
- Разработаны алгоритмы для параллельной визуализации на нескольких устройствах отображения многочисленных потоков мультимедийных данных в произвольно заданной конфигурации с удалённым управлением в реальном масштабе времени. Предложена архитектура системы для решения задач многопотоковой визуализации в тренажерно - обучающих системах (ТОС). Определены основные требования к архитектуре.
- Практическая значимость состоит в новых возможностях применения, в том числе при реализации концепции интегрированных тренажерных комплексов подготовки космонавтов, для тренажеров создаваемых Российской орбитальной станции (РОС) и пилотируемого транспортного корабля нового поколения (ПТК НП) «Орел», для авиационных тренажеров при совместном обучении членов экипажа выполнению навигационных задач.
- Разработан новый метод визуализации 3-D моделей сложных объектов, представляющих композицию объемных данных и функционально заданных поверхностей, для описания которых используются функции возмущения, а объемные данные - для формирования текстуры в виде восьмеричного дерева, которое окружает 3D-модель.
- Разработан метод синтеза объектов с множеством материалов для формирования сложных 3D-объектов из нескольких материалов с широким спектром механических и оптических свойств. Эффективные методы, адаптированные для реализации на графических процессорах, могут использоваться в научной визуализации, в задачах создания виртуальных моделей для цифрового изготовления реальных копий, для создания виртуальных методик обучения медицинским технологиям, для создания виртуальных моделей в авиационных тренажерах.
Результаты за 2023 год
Разработка методов повышения точности локализации объекта с использованием камер машинного зрения и маркеров. Разработка проекта системы быстрого определения опасности волны цунами вдоль побережья
Определение положения и ориентации объекта в реальном времени по изображению маркера требует обработки видеопотока. Это является ресурсоёмкой задачей, причём тем более ресурсоёмкой, чем большая точность результата требуется. Были разработаны алгоритмы для увеличения точности, которые включают в себя учёт геометрических искажений оптики, учёт размытия изображения оптикой, выделение дефектов, не подлежащих обработке и исключение их из обработки.
Использован метод минимизации ошибки, который требует вычисления целевой функции. Для реализации целевой функции хорошо подходят процессоры с архитектурой SIMD (используемой в GPU - графических процессорах). Для использования преимуществ данной архитектуры необходимо спроектировать алгоритм таким образом, чтобы каждый пиксел (или небольшая группа пикселов) изображения обрабатывался, во-первых, независимо от остальных, а во-вторых, одной и той же последовательностью операций. Целевая функция вычисляется как сумма целевых функций в отдельных пикселах. Это суммирование также можно частично выполнять на GPU, сгруппировав пикселы. Целевая функция в пикселе – это квадрат разности между значениями пикселов исходного и вычисленного изображения. Основной (и наиболее затратной) частью вычислительного алгоритма является определение значения пиксела c учётом заданной проекции и искажений. Моделируемые искажения включают в себя геометрические искажения и размытие. Для первых используется нелинейная модель с использованием рациональных квадрик, а размытие, будучи обусловлено множеством факторов, принимается гауссовым.
В результате исследований показано, что для восстановления смещения волной поверхности в очаге с заданной точностью, иногда достаточно обработать лишь часть записи (до первого максимума) одного глубоководного регистратора, если последний «правильно» расположен по отношению к очагу цунами.
Схема решения задачи оперативного прогноза цунами для заданного участка побережья предполагает, что через несколько минут после землетрясения сейсмическая служба определила местоположение эпицентра и оценила его магнитуду. Исходя из этого, определяется набор базисных источников, покрывающих область вокруг эпицентра. При более высоком значении магнитуды землетрясения нужно учитывать большее количество данных источников. Затем из созданной ранее базы рассчитанных мареограмм извлекаются те, что относятся к базисным источникам вокруг эпицентра. После того, как поступят записи с глубоководных регистраторов уровня океана и один или несколько регистраторов зафиксируют спад уровня после первого максимума, включается разработанный алгоритм восстановления очага. Через минуту вычисляется набор коэффициентов в линейной сумме рассмотренных базисных источников, которая аппроксимирует начальное смещение водной поверхности в очаге.
Исследование на макете возможностей отказоустойчивой доверенной системы контроля и управления с виртуальными контроллерами (СКУ ВК)
По результатам исследований на макете были уточнены требования к организации, функционированию, созданию и модернизации доверенных систем контроля и управления с виртуальными контроллерами (СКУ ВК) с усовершенствованным комплексом средств информационной безопасности (КСБ) и взаимодействующими с ним доработанными основными техническими и программными средствами системы.
Исследованы возможности согласованного функционирования следующих средств усовершенствованной доверенной СКУ ВК:
- встроенных средств информационной безопасности верхнего уровня (СИБВ ВУ), реализованных в составе основных программных средств СКУ ВК, установленных на компьютерах с функциями АРМ инженера, АРМ оператора, Сервера Приложений, Сервера Баз Данных;
- встроенных средств информационной безопасности нижнего уровня (СИБВ НУ), реализованных на компьютере с функциями виртуального контроллера;
- дополнительных программных средств информационной безопасности (СИБД): Системы Обнаружения Вторжений, Сервера Информационной Безопасности, Сервера Аналитики, АРМ Информационной Безопасности.
Выполненные исследования позволяют обеспечить эффективное комплексное применение современных средств информационной безопасности, встроенных в отказоустойчивую доверенную систему управления с виртуальными контроллерами для объектов критически важной информационной структуры без потери качества функционирования системы в режиме реального времени.
Исследование и развитие методов, технологий и программно-аппаратных средств на базе графических процессоров для формирования, обработки и отображения мультимедийных данных в реальном масштабе времени
Реконструкция 3D-формы из одного ракурса изображения представляет собой важную задачу, поскольку она служит основой для формирования новых представлений об объекте, наблюдаемом на одном изображении, но из другой точки зрения, с другой текстурой и освещением. По сравнению с большинством других задач компьютерного зрения реконструкция по одному ракурсу является крайне некорректной проблемой. Как следствие, необходимо сделать дополнительные предположения о том, что геометрия объекта, например, кусочно- плоскостная, форма из текстуры, форма из затенения или форма из расфокусировки. Такие подходы имеют ограничения, сложные по вычислениям и проблематичны для использования в интерактивном режиме.
Для визуализации используется метод отслеживания лучей, проходящих через каждый пиксель плоскости изображения от взгляда наблюдателя сквозь пирамиду видимости (объектное пространство). Лучи проецируются на базовую плоскость.
Вычислительный процесс для реализации метода распараллелен на графическом процессоре GPU 470 GTX. Это включало в себя шаги проекции и бинарного деления вокселей. Метод протестирован на нескольких реальных изображениях, сравнены полученные результаты с другими известными методами, оценен внешний вид, время вычисления, объем данных пользовательского ввода. Так как нельзя получить истинные значения глубины из одного ракурса, то не ставилась задача решения абсолютного сходства с исходными данными. Скорее стремились к правдоподобию реконструкции. Причем, так как обратные стороны объектов естественно невидимы во входном изображении, то реконструкции должны быть симметричными. Это может быть достигнуто путем простого зеркального отображения вычисленных значений глубины вдоль плоскости изображения. С помощью данного упрощения можно получить замкнутые представления 3D-объекта, используя карты глубины.
Для нахождения данных трехмерных точек необходимо вокселизировать оставшуюся часть. Чем меньше вокселей остается, тем большее сходство тестируемых объектов.
Предложен метод распознавания трехмерных объектов на основе скалярных функций возмущения и теоретико-множественной операции вычитания. Метод распознавания отличается от известных подходов тем, что в процессе проверки участвуют не только точки поверхности, но и объём.
Защиты ВКР
- Ремнев М.А. под руководством к.т.н. Лысакова К.Ф. успешно защитил ВКР на тему "Разработка алгоритма синхронизации виртуальной и реальной камер методом оптического потока" и получил диплом магистра
- Дмитриенко М.Ю. под руководством к.т.н. Лысакова К.Ф. успешно защитил ВКР на тему "Разработка программно-аппаратного кодека для передачи видео с минимальной задержкой" и получил диплом магистра
- Соломин М.Г. под руководством Таранцева И.Г. успешно защитил ВКР на тему "Разработка подсистемы захвата видео для системы Stadium Graphics" и получил диплом бакалавра
Результаты за 2022 год
Алгоритм высокоточной локализации объекта с использованием камер машинного зрения и маркеров с использованием высокопроизводительных платформ c архитектурой SIMD. Программные средства определения основных параметров волны цунами в источнике по одной записи части волнового профиля. Интегрированное решение задачи оперативного прогноза опасности волны цунами на заданном участке побережья.
Для решения задачи определения положения и ориентации объекта в реальном времени по изображению маркера был выбран метод минимизации ошибки, который требует вычисления целевой функции.
Разработан алгоритм определения целевой функции для локализации объектов с использованием камер машинного зрения и маркеров для реализации на графических процессорах (GPU) с архитектурой SIMD. Для использования преимуществ этой архитектуры алгоритм спроектирован таким образом, чтобы каждый пиксел (или небольшая группа пикселов) изображения обрабатывался, во-первых, независимо от остальных, а во-вторых, одной и той же последовательностью операций. На производительность алгоритма влияет множество факторов, но при прочих равных условиях, алгоритм, реализованный с использованием GPU, обеспечивает увеличение производительности примерно на порядок по сравнению с реализацией только на центральном процессоре (CPU).
Рассмотрена возможность определения примерных параметров волны в очаге цунами за возможно малое время. За основу берутся прямые измерения профиля волны донными датчиками давления. Сенсоры, аналогичные DART, расположены достаточно произвольно напротив зон субдукции. Вместе с тем, методами математического моделирования легко решается задача оптимизации мест расположения небольшого количества дополнительных сенсоров для того, чтобы через минимально возможное время волна цунами достигла ближайшего сенсора. Следует отметить, что это будет гарантированное время в так называемом наихудшем случае, когда эпицентр землетрясения в пределах данной зоны субдукции будет максимально (с точки зрения времени распространения волны) удален от системы сенсоров. До настоящего времени это подход «умного» расширения системы наблюдения, к сожалению, не получил развития.
Предложен и проверен в серии численных экспериментов новый критерий оптимальности расположения сенсоров системы наблюдения для своевременного определения параметров волны цунами в источнике. Численные эксперименты проводились на реальной батиметрии с использованием ранее разработанного специализированного вычислителя. Для служб предупреждения об опасности цунами интерес должно представлять такое расположение системы наблюдения, чтобы после определения параметров (амплитуды) в источнике цунами оставалось возможно больше времени до прихода волны на берег. Модельные расчеты показывают, что в этом случае оптимальное расположение датчиков должно быть другим, по сравнению с тем, которое обеспечивает определение параметров за наименьшее время. До настоящего времени авторам неизвестно практическое применение этой технологии.
Макетная реализация отказоустойчивой доверенной системы контроля и управления с виртуальными контроллерами (СКУ ВК) с усовершенствованным комплексом средств информационной безопасности (КСБ), взаимодействующим с основными средствами системы, в которых реализованы дополнительные функции, повышающие уровень информационной безопасности.
Реализован макет системы контроля и управления с виртуальными контроллерами (СКУ ВК) с доработанными основными средствами системы управления и с усовершенствованным комплексом средств информационной безопасности. Макет состоит из встроенных в систему и дополнительных средств, не взаимодействующих с системой. Зто позволяет исследовать возможности новых решений, повышающих уровень информационной безопасности систем управления в режиме реального времени. Созданы условия для исследования на макете существующих и новых подходов к обеспечению информационной безопасности значимых объектов критической информационной инфраструктуры и изучения возможностей комплексного применения широко распространенных традиционных и вновь разработанных средств обеспечения информационной безопасности с целью создания доверенных, надежно защищенных систем управления. Макет позволяет исследовать возможности комплексного обеспечения информационной безопасности без потери качества функционирования в режиме реального времени в отказоустойчивых доверенных системах контроля и управления с виртуальными контроллерами.
В 2022 году в лаборатории выполнили и успешно защитили дипломы студенты НГУ:
- Погодаев Никита Алексеевич под руководством Лысакова К.Ф. защитил ВКР бакалавра на факультете информационных технологий НГУ на тему "Отображение теней и полупрозрачных объектов в интерактивных системах виртуальной реальности".
- Соковнин Антон Максимович под руководством Лысакова К.Ф. защитил ВКР бакалавра на факультете информационных технологий НГУ на тему "Реализация алгоритма визуализации объемных данных в презентационной системе AllMix".
- Корнев Захар Дмитриевич под руководством Таранцева И.Г. защитил ВКР бакалавра на физическом факультете НГУ на тему "Ускорение алгоритма поиска и сравнения множества видеопоследовательностей".
- Ванданов Сергей Александрович под руководством Таранцева И.Г. защитил ВКР бакалавра на физическом факультете НГУ на тему "Исследование применимости и оптимизация распространенных алгоритмов выделения актера для бытовых систем видеоконференций".
- Пищев Иван Евгеньевич под руководством Таранцева И.Г. защитил ВКР бакалавра на физическом факультете НГУ на тему "Интеграция высокоскоростных камер в систему видеосудейства Форвард Рефери".
Результаты за 2021 год
Исследование и разработка подходов к решению задач высокоточной локализации объекта с использованием камер машинного зрения и маркеров.
Разработка программно-аппаратных средств для быстрого (в пределах минуты) расчета распространения волны цунами от источника до выбранного участка береговой линии.
Задача определения положения и ориентации объекта почти всегда возникает в реализации системы виртуальной и смешанной реальности. Чаще всего необходимо определять положение головы пользователя и/или контроллеров, используемых для управления виртуальными объектами. В компьютерных тренажерах, в частности космических, позиционирование головы оператора важно для правильной параметризации пирамиды видимости, вершина которой должна соответствовать голове наблюдателя. Не менее важно и позиционирование инструментов в руках оператора, для их правильного отображения в виртуальном мире. Разработан базовый алгоритм, определяющий положение четырехугольного маркера по изображению с камеры машинного зрения. Простота маркера была продиктована удобством отладки алгоритма и интерпретации результатов. Для экспериментов была использована монохромная камера, в результате которых подтверждена применимость разработанного алгоритма в задачах определения положения головы или инструментов в руках оператора для космических тренажеров, где рабочая область тестовой системы сопоставима с пространством, ограничивающим движения космонавта. Разработан и протестирован на реальных данных алгоритм локализации объекта с использованием камер машинного зрения по визуальному маркеру, а также алгоритм калибровки камеры с использованием рациональных квадрик в качестве модели искажений.
Было продолжено тестирование предложенного ранее спецвычислителя на базе вентильной матрицы программируемой пользователем (Field Programmable Gates Array - FPGA). Для обеспечения возможности проведения расчетов параметров волны практически до береговой линии метод сгущающихся сеток был адаптирован для применения разработанного ранее спецвычислителя на базе FPGA для численного моделирования распространения цунами от глубоководного участка океана до береговой линии. Расчеты профиля волны от модельного источника были проведены на реальном профиле глубин у побережья Японии. Полученные результаты позволяют говорить о перспективности разрабатываемой технологии для оперативного (в пределах нескольких минут после сейсмического события) прогноза опасности волны цунами на заданном участке береговой линии.
Разработка требований к макету системы с усовершенствованным комплексом средств информационной безопасности, взаимодействующим с основными средствами системы управления.
Определены требования к макету доверенной детерминированной системы контроля и управления реального времени с виртуальными контроллерами, на котором будут исследованы возможности применения встроенных в систему средств информационной безопасности, используемых совместно с усовершенствованным комплексом дополнительных средств информационной безопасности.
Возможности применения традиционных подходов к обеспечению информационной безопасности значимых объектов критической информационной инфраструктуры всё еще изучены недостаточно. Необходимо продолжать исследования существующих и поиск новых подходов к обеспечению информационной безопасности с целью создания доверенных, надежно защищенных систем управления реального времени.
Разработаны требования к макету усовершенствованной доверенной детерминированной системы контроля и управления реального времени с виртуальными контроллерами (СКУ ВК), снабженной встроенными и дополнительными средствами информационной безопасности, на котором будут исследованы возможности применения встроенных в систему средств информационной безопасности (СИБВ), реализованных на верхнем уровне системы (СИБВ ВУ) и на нижнем уровне (СИБВ НУ). Реализация макета позволит выполнить исследования, в результате которых может быть существенно повышен общий уровень информационной безопасности систем управления.
Результаты за 2020 год
Исследование возможности определения параметров очага подводного землетрясения (источника разрушительно волны цунами) по записи части профиля волны, полученной в одной точке (одной глубоководной гидрофизической станцией).
В последние годы наблюдается рост числа катастрофических наводнений сейсмической природы в различных регионах мирового океана и существенное усиление их влияния на жизнедеятельность населения в прибрежной полосе. Отметим, что в два года назад минуло 10 лет со дня катастрофического цунами 2004 г., возникшего у берегов Суматры (Индонезия) и унесшего сотни тысяч человеческих жизней. В этом году было 5-ти летие разрушительного цунами 11 марта 2011 года (Великое восточно-японское землетрясение), которое привело к экономическому ущербу в 1/4 годового бюджета Японии и оказало влияние на мировую экономику в целом (в частности, к отказу Германии от ядерной энергетики вследствие аварии на атомной электростанции Фукушима-1). Это было одно из сильнейших землетрясений в истории страны. Волны цунами смывали машины и дома. По оценке Центра Управления Катастроф и Снижения Риска (Center for Disaster Management and Risk Reduction, Germany), около 20000 человек погибли и более 1.000.000 лишились своих домов. Более миллиона зданий было повреждено. Япония лишилась заметной части человеческого и экономического потенциала. Экономический ущерб оценивается в рамках от 250 до 309 миллиардов долларов США. Оказалось, что современное общество не готово к природным катастрофам сейсмической природы такого масштаба.
Одним из центральных параметров любой системы предупреждения об опасности цунами является время, необходимое для оценки высоты волны перед различными участками побережья. Начальными данными для расчетов является оценка параметров смещения морского дна в источнике цунами. Не останавливаясь на описании различных способов получения этих параметров, выделим обработку записи профиля волны цунами, полученную на отдельно взятой глубоководной гидрофизической станции. Отметим, что с использованием спутниковых каналов связи получение данных измерений возможно в режиме реального времени, в процессе прохождения волны над донным датчиком давления.
Как правило, оценки параметров очага цунами делаются на основе записей целого периода волны. Время прохождения полного периода может занимать от 100 сек (для длины волны порядка 20 км) до 250 сек (для длины волны 50 км). Это занимает значительную часть времени добегания волны от источника до ближайшей точки побережья, которое составляет около 1200 сек для событий так называемой ближней зоны, характерных для побережья Камчаки и Курильских островов.
Проведенные численные эксперименты показывают, что в рамках метода предварительных вычислений хорошее приближение параметров очага цунами можно получить примерно по одной четверти полного профиля волны (практически, по данным от начального вступления до первого максимума).
Результаты за 2017 год
Исследование и разработка подходов одновременной локализации и построения карты для управления наземным транспортным средством.
Основной результат
Разработаны метод локализации управляемого объекта по визуальным маркерам, алгоритм начального предсказания позиции объекта, два подхода замыкания циклов. Предложенные подходы и методы позволили устранить или существенно снизить основные проблемы, препятствующие применению SLAM систем, основанных на использовании лидара, такие как:
- накопление ошибки локализации со временем;
- обязательное наличие одометра или инерциального датчика;
- большие погрешности в определении позиции управляемого объекта на однородной местности.
Разработанные подходы универсальны и могут быть применены к различным SLAM системам, основаным на использовании лидара.
Содержание работы
В существующих системах CoreSLAM, Gmapping и др. используется лидар для нахождения статических объектов в окружающем пространстве, относительно которых происходит локализация управляемого объекта, но информации полученной от данного устройства недостаточно для локализации в однородной местности с небольшой погрешностью. В связи с этим было предложено внедрить в систему дополнительный оптический датчик – камеру. Для позиционирования камеры предлагается использовать визуальные маркеры, расположенные в окружающей местности, с известными координатами. Таким образом, в качестве дополнительных входных данных в фильтр частиц, который используется в CoreSLAM, добавляются рассчитанные позиция и ориентация объекта по маркерам. Итоговый вес частицы представлен как сумма весовых оценок локализации по данным с лидара и локализации по маркерам. Стоит отметить, что наличие визуальных маркеров в окружении не жесткое требование для корректной работы SLAM системы, а дополнительная возможность для более точной локализации управляемого объекта и построения карты местности.В существующих системах CoreSLAM, Gmapping и др. используется лидар для нахождения статических объектов в окружающем пространстве, относительно которых происходит локализация управляемого объекта, но информации полученной от данного устройства недостаточно для локализации в однородной местности с небольшой погрешностью. В связи с этим было предложено внедрить в систему дополнительный оптический датчик – камеру. Для позиционирования камеры предлагается использовать визуальные маркеры, расположенные в окружающей местности, с известными координатами. Таким образом, в качестве дополнительных входных данных в фильтр частиц, который используется в CoreSLAM, добавляются рассчитанные позиция и ориентация объекта по маркерам. Итоговый вес частицы представлен как сумма весовых оценок локализации по данным с лидара и локализации по маркерам. Стоит отметить, что наличие визуальных маркеров в окружении не жесткое требование для корректной работы SLAM системы, а дополнительная возможность для более точной локализации управляемого объекта и построения карты местности.Чтобы избежать требования на наличие внешнего устройства для получения одометрии, было предложено создать алгоритм для первоначальной оценки позиции объекта в случае отсутствия одометра. Основная идея заключается в следующем. На каждой итерации после использования фильтра частиц система сохраняет N частиц с наибольшими весами. Вначале каждой итерации, система располагает только двумя последними наборами частиц. То есть на шаге m система имеет два множества точек Km-1 и Km-2. Чтобы получить первоначальное предсказание позиции объекта (перед применением фильтра частиц), предлагается провести линейную экстраполяцию между всеми парами точек из двух множеств с последующим вычислением веса для каждой частицы из полученного набора с учетом текущих данных лидара и глобальной карты препятствий. Частица с наибольшим весом выбирается в качестве начального предсказания позиции управляемого объекта.Разработанный алгоритм замыкания циклов состоит из двух частей, которые направлены на уточнение позиции управляемого объекта, предсказанной с помощью фильтра частиц по глобальной карте препятствий (карта, содержащая все данные полученные с лидара). Первая часть сохраняет карту препятствий и текущую оценку позиции управляемого объекта на данной карте при условии, что объект находится в неисследованной области. Неисследованная область определяется с помощью проверки принадлежности предсказанной позиции к некоторой окрестности уже сохраненных точек. В случае попадания предсказанной позиции в окрестность сохраненной точки, выполняется вторая часть алгоритма замыкания циклов, которая проводит повторную локализацию по соответствующей сохраненной карте. Поскольку точность карты препятствий связана с погрешностью оценки позиции объекта и погрешность накапливается со временем, ранее сохраненная карта не менее точна, чем глобальная карта. Таким образом, проведя повторную оценку позиции по сохраненной карте можно сократить накопленную ошибку оценки позиции объекта (см. рис.).
Недостатком данного подхода является большой расход оперативной памяти, связанный с хранением глобальных карт препятствий. Для решения этой проблемы в алгоритме замыкания циклов было предложено сохранять не глобальные карты препятствий с обработанными данными лидара, а локальные, которые содержат некоторый набор сырых данных с лидара и позиции управляемого объекта в момент сбора информации. Для решения проблемы связанной с повторной локализацией управляемого объекта по сохраненной карте использовался метод выравнивания сканов, основанный на итеративном алгоритме ближайших точек.
Использование современных компьютерных архитектур для обработки данных на примере решения задачи распространения волн.
Основной результат
Разработаны аппаратные и программные методы значительного ускорения расчётов высот волны до момента прибытия цунами к берегу без ущерба для точности. Предложены методы реализации разностных вычислительных схем Мак-Кормака на архитектуре FPGA. Предложенные методы позволяют сократить время моделирования волны цунами для более раннего определения опасных прибрежных зон.
Содержание работы
В последние годы наблюдается рост числа катастрофических наводнений сейсмической природы в различных регионах мирового океана и существенное усиление их влияния на жизнедеятельность населения в прибрежной полосе. Современные средства компьютерного моделирования позволяют достаточно точно рассчитать профиль по крайней мере первого периода волны цунами по известной начальной форме волны в источнике (то есть над зоной подвижки морского дна). Однако, важнейшим параметром любой системы предупреждения об опасности цунами является время, необходимое для формирование обоснованного прогноза.В последние годы наблюдается рост числа катастрофических наводнений сейсмической природы в различных регионах мирового океана и существенное усиление их влияния на жизнедеятельность населения в прибрежной полосе. Современные средства компьютерного моделирования позволяют достаточно точно рассчитать профиль по крайней мере первого периода волны цунами по известной начальной форме волны в источнике (то есть над зоной подвижки морского дна). Однако, важнейшим параметром любой системы предупреждения об опасности цунами является время, необходимое для формирование обоснованного прогноза.Исходными данными для любой системы предупреждения о цунами являются параметры источника волны. После восстановления начального смещения водной поверхности в очаговой области следует решать прямую задачу распространения волны цунами от известного очага до защищаемых участков на побережье. Обычно этот процесс моделируется путём численного решения системы дифференциальных уравнений гидродинамики в рамках приближения теории мелкой воды, применяя один из разработанных и протестированных методов. Службой предупреждения о цунами США используется программный пакет MOST (Method of Splitting Tsunamis). Ввиду необходимости выполнения условия устойчивости, накладывающего ограничения на величину шага по времени, численный расчёт на достаточно детальной сетке может потребовать слишком много времени и может не дать оценок ожидаемых высот волны до момента прибытия цунами к берегу. В связи с этим авторами были разработаны аппаратные и программные методы значительного ускорения этих расчётов без ущерба для их точности.В пакете MOST для численного моделирования движения волны цунами по водной акватории используется следующий эквивалентный вид так называемой системы мелкой воды без учёта внешних сил (донное трение, сила Кориолиса и т.д.).
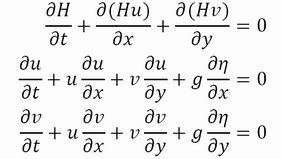
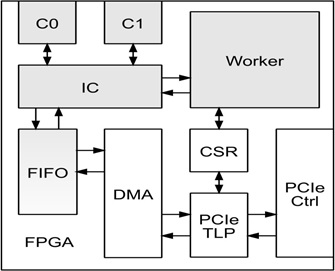
Для моделирования был использован аппаратный вычислитель на базе FPGA Xilinx Virtex-7 VC709. Блок-схема архитектура спецпроцессора представлена на рисунке.
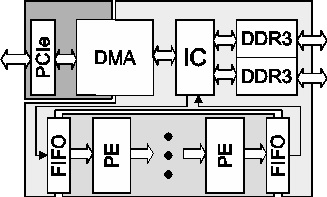
Помимо самого вычислителя спецпроцессор имеет контроллеры памяти DDR3, контроллер PCIe, модуль DMA, обеспечивающий взаимодействие вычислителя с памятью компьютера-хоста в режиме прямого доступа. Данные поступают в вычислитель из памяти через FIFO, что позволяет легко варьировать частоту отдельных вычислительных блоков, подстраиваясь под конкретный кристалл FPGA и характеристики внешней памяти и интерфейсов. Сам вычислитель, в зависимости от доступных ресурсов FPGA, состоит из одного или нескольких процессорных элементов. Спроектированный вычислитель на уровне алгоритмов был протестирован с применением технологий HLS. Модули, обеспечивающие работу всего процессора, были протестированы с помощью RTL-симуляторов. Помимо самого вычислителя спецпроцессор имеет контроллеры памяти DDR3, контроллер PCIe, модуль DMA, обеспечивающий взаимодействие вычислителя с памятью компьютера-хоста в режиме прямого доступа. Данные поступают в вычислитель из памяти через FIFO, что позволяет легко варьировать частоту отдельных вычислительных блоков, подстраиваясь под конкретный кристалл FPGA и характеристики внешней памяти и интерфейсов. Сам вычислитель, в зависимости от доступных ресурсов FPGA, состоит из одного или нескольких процессорных элементов. Спроектированный вычислитель на уровне алгоритмов был протестирован с применением технологий HLS. Модули, обеспечивающие работу всего процессора, были протестированы с помощью RTL-симуляторов. Для практической реализации и тестирования были использованы платформа VC709 на базе кристалла Virtex-7 xc7vx690-2 и SLEDv7 на базе кристалла Virtex-6 xc6vsx315-1.
Тесты проводились на батиметрии южной части Японии (см. рис.):
- Размер 3000х2496 точек
- Шаги сетки 0.003 и 0.002 градуса (280.6 и 223 м)
- границы массива от 131 до 140 градусов В Дот 30.01 до 35 градусов С Ш
Временной шаг составлял 0.5 секунд.
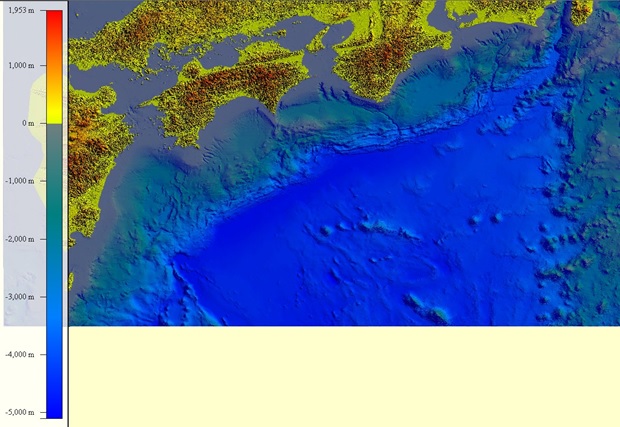
По результатам моделирования, время распространения волны от южной границы батиметрии до побережья составило 25секунд. При этом время достижения волной берега составило 3200 секунд модельного времени.По результатам моделирования, время распространения волны от южной границы батиметрии до побережья составило 25секунд. При этом время достижения волной берега составило 3200 секунд модельного времени.Данные результаты позволяют сделать вывод о целесообразности применения программно-аппаратного решения на базе FPGA для моделирования распространения волн цунами после произошедшего события.
Результаты за 2016 год
Разработка методов визуальной имитации процессов внекорабельной деятельности космонавтов на наружной поверхности орбитальной станции.
Основной результат
Проведены исследования особенностей внекорабельной деятельности космонавтов. Разработан метод визуальной имитации наружной поверхности Международной космической станции с использованием технологии мультифокальных дисплеев, направленный на устранение влияния основных факторов, присущих традиционным наголовным дисплейным системам:
- недопустимые ошибки оператора при определении расстояний и размеров объектов;
- рассогласование стереоскопического и аккомодационного механизмов человеческого зрения;
- ограничение времени тренировки в связи опасностью для зрения оператора.
Создан прототип системы визуализации для тренажеров внекорабельной деятельности с применением наголовного бифокального дисплея.
Содержание работы
В основе успешности применения классических компьютерных тренажеров лежит близость зрительного восприятия человеком реальной и виртуальной визуальной обстановки в тех случаях, когда целевые объекты, на которые ориентируется человек, находятся от него на значительном расстоянии. Такие типы визуальной обстановки успешно имитируются с помощью проекционных устройств, экраны которых устанавливаются на расстоянии 6 и более метров от обучаемого или с помощью коллимационной оптики, фокусирующей человеческих глаз на бесконечность. Для отработки непосредственного взаимодействия человека с близкими целевыми объектами (к которой в полной мере относится отработка деятельности космонавта на внешней поверхности космической станции) традиционные методы визуальной имитации не применимы, так как в них на малых расстояниях до целевых объектов перестают согласованно работать механизмы зрительного восприятия: аккомодация -фокусировка глаза на близкий целевой объект и конвергенция - встречное движение глаз, в результате которого обе зрительные линии сходятся вместе на целевом объекте.
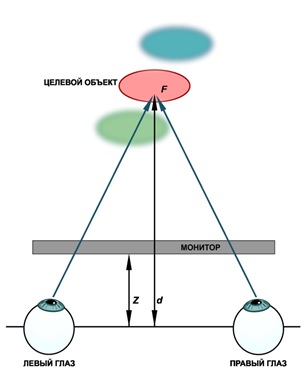
Особенности зрительного восприятия близких объектов.
F - точка пересечения зрительных осей;
Z- расстояния от глаз до плоскости монитора;
d - расстояние от глаз до точки фиксации взгляда на поверхности целевого объекта.
Попытка применения традиционных дисплейных стереосистем приводит к возникновению конфликта – глаз аккомодирует на фиксированное расстояние до плоскости экрана (Z - на схеме), независимо от того, в какой точке виртуального пространства (ближе или дальше) пересекаются зрительные оси глаз вследствие конвергенции (точка F - на схеме на расстоянии d от глаза). В результате у человека появляется бинокулярный стресс, утомление глаз, головная боль, тошнота и т.д. Кроме того, обучаемому прививаются ложные навыки, связанные с недопустимым ошибочным определением расстояний и размеров объектов.
Для устранения или существенного уменьшения перечисленных проблем был предложен метод, основанный на применении наголовного бифокального дисплея и разработана специализированная четырехканальная система визуализации. Оптическая схема и внешний вид дисплея приведены на рисунках:
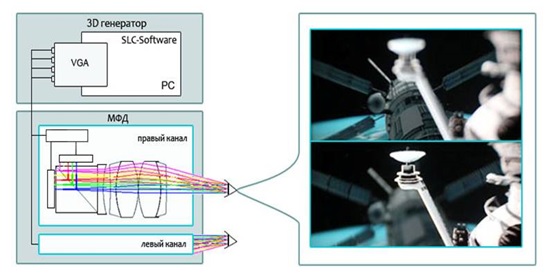
Бифокальная схема, обладающая двумя планами фокусировки

Внешний вид наголовного мультифокального дисплея
В отличии от традиционных стерео систем визуализации в разработанной системе генерируется по два изображения для каждого глаза. При этом каждое каждый пиксел генерируемого изображения наряду с плоскими координатами XY получает третью координату D=1/d, где D – глубина в диоптриях, d – расстояние до видимого участка объекта в метрах. Пара изображений для одного глаза соответствует двум фокусным планам - 1м и 4м. В целях оптимизации процесса отображения разработан специальный шейдер, который на этапе постобработки генерирует два изображения, соответствующие разным фокусным планам на основе одного готового изображения стереопары. Шейдер модифицирует яркость каждого пиксела в зависимости от разности между глубиной изображения в данном пикселе и целевым фокусным планом. Зависимость яркости от глубины подобрана с учетом психофизиологических свойств зрения так, чтобы при оптическом смешивании изображений двух фокусных планов достигалась равномерность аккомодационного восприятия. На рисунках ниже проиллюстрированы два фокальных изображения для одного глаза в типичной сцене тренинга внекорабельной деятельности космонавтов.

Cлева - изображение для дальнего фокусного плана, cправа - для ближнего плана.
Расстояние до антенн на ближнем плане ~ 1м.

Точка наблюдения смещена на 2м назад от предыдущего рисунка
Четыре изображения предназначенные для одного кадра формируются в виде составного единого изображения и передаются посредством HDMI интерфейса на бифокальный дисплей, который с помощью окулярной оптоэлектронной схемы для каждого глаза формирует по два плана изображения.
Такая технология не имеет методической погрешности, как при монокулярном, так и при бинокулярном зрении. В первом случае виртуальное пространство воспринимается объёмным за счет аккомодации глаза на точки фиксации взгляда F с глубиной d. При этом изображение вокруг точки фиксации становится резким, а изображение удалённых (d<DF) или более близких точек (d>DF) в поле зрения естественным образом дефокусируется. Во втором случае, при стерео зрении аккомодация и конвергенция глаз приходится на одни и те же точки фиксации F. Возникает процесс стереопсиса, который усиливает объёмное ощущение пространства. Таким образом, в области интереса изображение оказывается и резким и слитным (без диплопии). Появление визуального дискомфорта принципиально невозможно. Дефокусировка изображений вне области фиксации остаётся, что является необходимой компонентой достоверного когнитивного восприятия пространства. Технология обеспечивают согласованное стереоскопическое и аккомодационное зрение при большом динамическом диапазоне расстояний до целевых объектов (от 80 см до бесконечности).
Опытный образец разработанной системы получил положительную оценку в ФГБУ «НИИ ЦПК имени Ю.А. Гагарина» в качестве перспективной технологии для создания тренажеров внекорабельной деятельности космонавтов. Поданы заявки на изобретение 2015147672 и на полезную модель PCT/RU 2015/000956.
Разработанный метод визуальной имитации может использоваться при создании перспективных систем дистанционного управления различными транспортными средствами, роботизированными манипуляторами, в авиационных тренажерах дозаправки в воздухе, в задачах микрохирургии и др.
Результаты за 2015 год
Исследование методов построения и разработка технологической концепции виртуальной деятельностной коммуникационной среды, базирующейся на облачной архитектуре.
Основной результат
Разработана технологическая концепция образовательной платформы для смешанного обучения географически удаленных пользователей. Дистанционное очное обучение реализуется посредством переноса образовательного процесса в разделяемую трехмерную виртуальную среду, в которой участники способны взаимодействовать друг с другом и моделями учебных объектов. Предложенный подход позволил на порядок снизить требования к пропускной способности интернет каналов, повысив равнодоступность обучения.
Содержание работы
В настоящее время широкое распространение и признание в образовании получили технологии Blending Learning. Blended Learning, или cмешанное обучение - это образовательная концепция, в рамках которой обучаемый получает знания и самостоятельно онлайн, и очно с преподавателем. Т.е. смешанное обучение позволяет совмещать традиционные методики очного обучения и инновационные интернет технологии передачи знаний.
Современные системы дистанционного обучения обладают мощными средствами организации, наглядного представления и интернет доставки учебных материалов, но не обладают адекватными инструментами для взаимодействия обучаемых с преподавателем и между собой. Таким образом применение смешанного обучения в полностью дистанционном режиме невозможно. Для решения этой задачи авторами предложена концепция дистанционной очности, базирующаяся на переносе процесса очного обучения в разделяемую трехмерную виртуальную среду, в которой преподаватель и обучаемые представлены собственными трехмерными аватарами, способными взаимодействовать друг с другом и самим виртуальным пространством (перемещаться, разговаривать, жестикулировать, работать с виртуальной классной доской, взаимодействовать с виртуальными моделями объектов и процессов, с абстрактными знаковыми моделями).
В отличие от таких широко применяемых инструментов взаимодействия как вебинары и веб конференции в предлагаемом подходе взаимодействие между пользователями достигается за счет эффекта погружения участников в виртуальную среду, применения голосового, эмоционального и жестового общения опосредованного через управление пользовательскими аватарами. Объемы обмениваемой через интернет информации, а следовательно и требования к пропускной способности интернет каналов у конечных пользователей в этом случае снижаются на порядок, что создает предпосылки для общедоступности качественного смешанного обучения.
Предлагаемая технологическая платформа смешанного обучения обладает облачной архитектурой. Хранение данных и большинство вычислений, связанных функционированием виртуальной среды, осуществляется на специальных серверах виртуальной среды. Отображение традиционного образовательного контента на компьютерах конечных пользователей осуществляется с помощью стандартного интернет браузера, а для отображения виртуальной среды применяется тонкий клиент, что в свою очередь позволяет существенно снизить требования к компьютерам конечных пользователей.
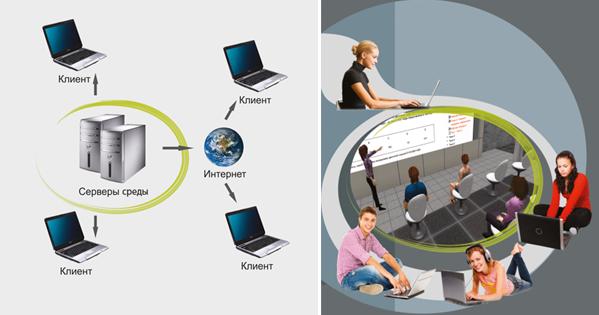
Развитие технологий массового открытого онлайн обучения (MOOC технологий) диктует необходимость поддержки одновременного участия в обучении большого числа пользователей (вплоть до тысяч и десятков тысяч пользователей). Для реализации этой возможности авторами была разработана концепция распределенной виртуальной среды, в которой данные о среде и основные вычислительные операции могут распределяться на практически неограниченном количестве серверных станций. При этом пользователи разделяются на изолированные группы одновременно присутствующих в виртуальных аудиториях и взаимодействующих между собой обучаемых, поэтому требования к пропускной способности интернет каналов конечных пользователей по мере их общего роста не возрастает.

Виртуальное очное обучение является важной, но не единственной необходимой компонентой смешанного обучения. Для успешного сочетания виртуального очного и заочного дистанционного обучения авторами разработаны методы интеграции виртуальной среды с популярными системами управления обучением (например, со свободно распространяемыми системами Moodle или Оpen eDX) в единую платформу смешанного обучения.
Кроме того авторами предложены методы интеграции платформы смешанного обучения с автоматизированными системами управления учебными заведениями. В результате такой интеграции регистрация пользователей и предоставление доступа к образовательному контенту регламентируется не в рамках платформы, а на уровне автоматизированной системы управления ВУЗом, что устраняет дублирование информации и рутинных операций по ее ручному вводу, повышает общую эффективность и надежность функционирования всей IT-инфраструктуры учебного заведения.
Разработка программно-аппаратного комплекса на базе FPGA для алгоритмов обработки сейсмологических данных в режиме реального времени
Основной результат
Разработаны архитектуры вычислительных конвейеров для решения СЛАУ большой размерности на базе программируемой логики FPGA, реализующие метод Якоби, блочное LU-разложение, стабилизированный метод BiCGSTAB. Разработанные конвейеры эффективны для вычислений с плавающей точкой на FPGA. Предложеные архитектуры применимы как для создания спецпроцессоров в составе ПК, так и для портативных вычислительный устройств для работы в полевых условиях.
Содержание работы
При обработке сейсмических данных, одним из самых трудоемких этапов является решение систем линейных алгебраических уравнений (СЛАУ) большой размерности. На данный момент, для решения систем линейных уравнений используются различные методы распараллеливания вычислений – применение вычислительных кластеров и использование GPGPU (General-Purpose Graphics Processing Units, вычисления на GPU). Современная программируемая логика FPGA (Field-Programmable Gate Array) обладает возможностью параллельно исполнять до сотен тысяч параллельных потоков исполнения, одновременно создавая специализированные вычислительные конвейерные архитектуры. Кроме того, современные FPGA имеют возможность эффективной работы над числами с плавающей запятой. Всё это позволяет создавать специализированные вычислители (спецпроцессоры), увеличивающие скорость решения различных математических задач.
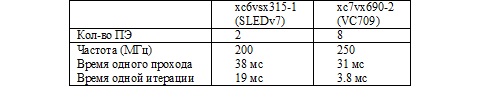
В качестве основы спецпроцессора были предложены два устройства на базе FPGA: отладочная плата VC709 фирмы Xilinx на базе кристалла семейства Virtex-7 (XC7VX690T) и плата SLEDv7 на базе кристалла семейства Virtex-6 (XC6VSX315T), созданная в лаборатории 13 Института Автоматики и Электрометрии СО РАН. Обе платы имеют схожее устройство, и представляют собой модули расширения PCI Express для ПК, на которых, помимо FPGA, находятся два разъема SO-DIMM для модулей памяти DDR3. Всего, FPGA доступно два независимых банка памяти DDR3, c суммарным объемом до 8 ГБ. Различия плат заключаются в установленном кристалле FPGA, скоростью интерфейсов и набором периферийных устройств.
В ходе работы была разработана универсальная архитектура спецпроцессора, пригодная для использования в различных задачах, обеспечивающая:
- обмен данными между памятью хоста и внешней памятью через PCIe в режиме DMA;
- доступ к памяти вычислительным блокам по универсальному протоколу AXI;
- управление вычислителем через набор регистров PCIe;
- управление и обработку прерываний (Interrupt Request).
Архитектура спецпроцессора была реализована и протестирована на отладочных платах SLEDv7 и Xilinx VC709. Было произведено тестирование производительности с применением программного обеспечения для ОС Windows. Реальная скорость обмена данными между памятью спецпроцессора и компьютера составила 1200 - 1300 МБ/с. Также, в ходе тестировании архитектуры было выяснено, что при чтении из памяти большими блоками спецпроцессор обеспечивает 88%-ую загрузку каналов памяти – реальная пропускная способность, доступная вычислителям составляет 10,7 ГБайт/с на канал.
Также, результатом работы является создание модулей матричных и векторных операций:
- Скалярное произведение векторов
- Умножение матрицы на вектор
- LU-разложение блока матрицы
- Перемножение блоков матрицы
С помощью этих блоков, возможна реализация различных алгоритмов, использующих матричные операции, в том числе алгоритмов решения СЛАУ. Ключевой особенностью разработанных модулей является использование чисел с плавающей запятой двойной точности (64 бита) стандарта IEEE-754. Ценность разработанных вычислительных модулей заключается в масштабируемости, что позволяет адаптировать их к различным аппаратным решениям, не изменяя архитектуру.
В результате работы были созданы вычислители, реализующие методы решения СЛАУ: метод Якоби, блочное LU-разложение, стабилизированный метод бисопряжённых градиентов (BiCGSTAB).
Производительность реализаций итерационных методов (метода Якоби и BiCGSTAB) зависит от пропускной способности памяти спецпроцессора. Для спецпроцессора на базе платы VC709 время одной итерации метода Якоби для матрицы размера N=8192 составило 23.83 мс, метода Якоби – 47.78 мс. В среднем, спецпроцессор обеспечивает ускорение в 2.6 раз по сравнению с однопоточной реализацией на CPU Intel Core i7-3770K @ 3.40GHz. (Загрузка кристалла ~25%, Энергопотребление < 20W)
Производительность реализации LU-разложение зависит от выбранного размера блока, что в свою очередь зависит от объема использованного FPGA. Для кристалла XC7VX690T максимальный размер блока равен 64. В этом случае, разложение матрицы размером N=8192 занимает 15 секунд, что в 11.5 раз быстрее однопоточной реализациии на CPU. (Загрузка кристалла ~75%, Энергопотребление < 20W)
Заключение
В работе показано, что применение современных FPGA позволяет эффективно реализовывать параллельное исполнение множества алгебраических операций с плавающей точкой. Результатом работы является архитектура вычислительных конвейеров для реализации ряда методов решения СЛАУ большой размерности. Ценность разработанных вычислительных конвейеров заключается в масштабируемости, что позволяет адаптировать их к различным аппаратным решениям, не изменяя архитектуру. Применение разработанных вычислительных конвейеров позволяет использовать спецвычислители на базе FPGA как в качестве ускорителя этапов решения задач в области сейсмологии, так и в качестве автономных мобильных вычислительные устройства для работы в полевых условиях.
Результаты за 2014 год
Исследование методов визуальной имитации технологических процессов орбитального мониторинга земной поверхности.
Созданы алгоритмическая и программная модели для отработки навыков визуально-инструментальных наблюдений (ВИН) и мониторинга поверхности Земли с борта космического аппарата.
Область применения: в системах компьютерной генерации изображения тренажеров для отработки навыков в области геофизических исследований и мониторинга Земли с борта космического аппарата методами ВИН.
В результате проведенных исследований установлено, что для обеспечения отработки космонавтом-оператором профессиональных навыков выполнения задач ВИН необходимо, чтобы система моделирования внешней визуальной обстановки обеспечивала формирование и отображение управляемых в реальном масштабе времени цветных динамических изображений земной поверхности, соответствующих условиям наблюдения в иллюминаторах пилотируемых космических аппаратах (ПКА) как невооруженным глазом, так и через бортовые инструментальные средства визуального наблюдения и отвечала следующим требованиям:
- возможность формирования в поле зрения бортового средства наблюдения изображения подстилающей поверхности Земли по трассе полета ПКА для любого суточного витка, соответствующего заданным баллистическим параметрам орбитального полета;
- высокий уровень географического подобия формируемого изображения земной поверхности;
- возможность проективных преобразований формируемого изображения с учетом кривизны Земли при ведении оператором наблюдений невооруженным глазом от надира к горизонту и моделировании изменений пространственного положения оптической оси бортового средства наблюдения;
- высокая точность координатной привязки объектов наблюдения, представленных в цифровой визуальной модели (ЦВМ) Земли;
- высокий уровень детализации объектов земной поверхности;
- воспроизведения объектов ВИН с учетом перекрытия элементами ПКА, времени года, уровня облачности и дымки.
Удовлетворить выявленные требования удается за счет создания реалистичной модели визуальной обстановки на основе реальных космических цифровых снимков земной поверхности, которые сведены по цвету и очищены от облачности. Для представления текстурных данных используется проекция Меркатора. На самом низком уровне детализации (первом уровне) текстура земной поверхности имеет размер 512×512 пикселей, а на каждом последующем уровне ширина и высота увеличиваются вдвое. При использовании проекции Меркатора пространственное разрешение (расстояние на поверхности Земли, которое представлено одним пикселем на текстуре) зависит от используемого уровня текстурной детализации и широты отображаемой точки.
Таким образом, из исходных снимков с разрешением 15-30 метров на тексел формируются данные для каждого из используемых уровней детализации текстуры земной поверхности. В каждом наборе данных в растровом формате представлены фрагменты изображений земной поверхности размером 256×256 пикселей. Фрагменты хранятся таким образом, что информация о двух географически близких точках в большинстве случаев находится рядом и на жестком диске ЭВМ. Это достигается за счет использования псевдо-Гильбертовых кривых для прямоугольных областей произвольного размера, алгоритм генерации которых был создан на основе работы Zhang J. et al. Такая организация данных позволяет эффективно осуществлять загрузку с диска необходимых участков текстур и визуализировать ЦВМ Земли от 85° южной широты до 85° северной широты с пространственным разрешением 15-30 метров на тексел. При этом возможна плавная трансфокация угла обзора от 110° до 2°. На практике система позволяет имитировать десятикратную скорость пролета ПКА, характерное время прохождения одного витка которых приблизительно составляет 90 минут.

В ходе работы над проектом подготовлен ряд статей и докладов на международных конференциях. Значимость результата исследований подтверждена патентом на полезную модель № 136618.
Результаты за 2013 год
Разработана архитектура вычислительного высокопроизводительного конвейера для решения задачи моделирования распространения волн цунами на базе спецвычислителей, имеющих в своем составе FPGA в качестве процессорного устройства и динамическую память.
Область применения: в области математического моделирования числовых и разностных схем с целью наблюдения и прогнозирования природных явлений.
Для моделирования распространения волны цунами применялась линейная система уравнений мелкой воды в виде, используемом мировыми центрами предупреждения (такая гиперболическая система, предложенная В.А. Титовым, допускает симметризацию с последующим использованием метода расщепления). В работе рассмотрен вариант решения задачи моделирования цунами с использованием FPGA и предложен масштабируемый вычислительный конвейер для FPGA семейств Virtex-5, Virtex-6 и Virtex/Kintex-7 на языке описания аппаратуры VHDL.
Предложенный вычислительный конвейер был реализован на базе двух спецвычислителей:
- на базе спецвычислителя FD842 (FPGA Xilinx xc5vlx30t). Было выяснено, что вычислитель может работать на частоте 62.5 МГц. На реализацию предложенного базового конвейера было затрачено более 90% объема кристалла, что не позволило использовать внешнюю динамическую память. В ходе тестирования было выяснено, что предложенный метод взаимодействия без DRAM (последовательная постраничная запись в FPGA) не дает ожидаемого эффекта (по сравнению с использованием графических ускорителей) из-за накладных расходов на обработку прерываний в драйвере (85% времени вычислитель простаивает в ожидании данных от ПК).
- на базе спецвычислителя SLEDv7 (FPGA Xilinx xc6vsx315t). Данный спецвычислитель имеет 2 независимых контроллера внешней динамической памяти DDR3. Емкость кристалла позволила реализовать вычислительный конвейер с коэффициентом масштабирования 10, а также использовать имеющуюся на борту внешнюю память для хранения исходных данных и промежуточных результатов. В данный момент происходит отладка программного обеспечения для запуска серии реальных тестов, но по результатам моделирования, итоговое увеличение производительности составит порядка 100 раз по сравнению с реализацией на базе спецвычислителя FD842.
В ходе работы был создан вычислительный конвейер для решения задачи моделирования распространения волны цунами. Данный конвейер разработан таким образом, что его можно легко масштабировать под используемый спецвычислитель, исходя из исполдьзуемого кристалла FPGA, а также наличия и количества внешней памяти. Также были разработаны принципы проектирования аппаратных спецвычислителей на базе FPGA для решения задач математического моделирования, особенностью которых являются многопроходность и использование большого количества начальных и промежуточных данных.
В настоящий момент в лаборатории закончена разработка нового аппаратного решения SLEDv7 на базе кристалла xc6vsx315t. Данный аппаратный комплекс обладает большим объемом логических элементов и содержит в себе большое количество блоков DSP, что позволяет сократить затраты на логические элементы. Помимо этого, использование таких блоков позволяет повысить тактовую частоту вычислителя и, соответственно, производительность. По результатам моделирования, использование предложенного аппаратного комплекса позволяет увеличить конвейер в 10 раз. С учетом пропускной способности интерфейсов памяти DDR3, установленной на данной плате итоговое увеличение производительности по сравнению с реализацией на аппаратном решении FD842 составляет порядка 100 раз.
В ходе выполнения работы была подготовлена и опубликована статья "FPGA Based Hardware Accelerator for High Performance Data-Stream Processing" (Pattern Recognition and Image Analysis, 2013, Vol. 23, No. 1, pp. 26–34).
По результатам программного моделирования и практического тестирования на двух программно-аппаратных комплексах были выявлены основные особенности, которые необходимо учитывать при выборе аппаратной платформы для математического моделирования подобных задач:
- Необходимо наличие внешней динамической памяти, соединенной непосредственно с вычислителем FPGA.
- Наличие двух независимых банков памяти позволяет существенно увеличить производительность вычислительного конвейера за счет распараллеливания независимых этапов вычислений.
- Объем установленной динамической памяти менее чем 4 ГБ может быть недостаточен для хранения исходных и промежуточных данных моделирования.
- Логический объем вычислителя FPGA должен быть не менее чем FPGA xc5vlx50t.
- Программная реализация драйвера аппаратного комплекса должна учитывать необходимость обработки большого количества прерываний (не менее 100 Гц) и своевременного обеспечения данными вычислительного комплекса.
Результаты за 2012 год
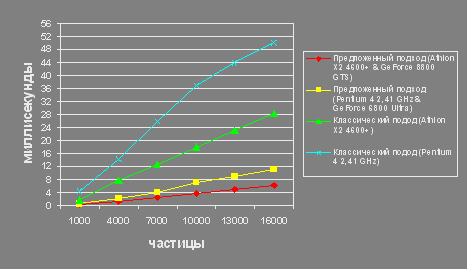
Предложены новые методы реализации системы частиц на стандартных графических акселераторах, обеспечивающие оптимальное соотношение между скоростью обработки частиц и качеством визуализации спецэффектов. Для обеспечения быстродействия предложен метод распределенной обработки анимационных составляющих спецэффекта. Обработка параметров анимации частиц осуществляется на пиксельном конвейере графического акселератора, а параметров анимации формы – на вершинном конвейере видеокарты. Разработаны алгоритмы и программное обеспечение для реализации предложенных методов на стандартных графических акселераторах.
  
Применение графического акселератора в качестве математического сопроцессора обеспечило пятикратное увеличение производительности по сравнению с классической реализацией.
Разработаны имитационная модель и программно-алгоритмические средства для моделирования поведения плотных автомобильных потоков на сети дорог. Модель обеспечивает реалистичное динамическое распределение автомобилей в пределах видимости наблюдателя, стабильность, предсказуемость и управляемость в широком диапазоне параметров.
Разработана интеллектуальная система управления виртуальным автомобилем в плотном дорожном трафике. Управление реализовано в виде набора допустимых маневров, применяемых в зависимости от текущей дорожной обстановки. Для каждого из автомобилей на каждом кадре принимается решение о продолжении выполнения текущего маневра или перехода на выполнение другого маневра. Разработаны и реализованы алгоритмы, представляющие следующие манёвры: движение по заданному на графе маршруту, смена полосы, обгон, остановка, проезд ответвления, проезд перекрёстка (регулируемого и нерегулируемого), объезд препятствия (в том числе и динамического), препятствование движению другого транспортного средства (полицейский обгон и экстренное торможение). Каждый из манёвров на дороге представлен соответствующим геометрическим описанием, которое позволяет точно рассчитать поведение участвующих в нём автомобилей, что в свою очередь позволяет принять однозначно определённое решение по дальнейшему распределению маневров для каждой из машин.
Предложенные алгоритмические решения могут использоваться в автомобильных тренажерах, в системах планирования и организации дорожного движения в качестве легко конфигурируемого тестового инструмента.
Разработана архитектура платы на базе FPGA и создано устройство для ускорения решения задачи поиска олигонуклеотидного мотива (сигнала) в геномной последовательности, которая является весьма распространенной задачей в области выявления сайтов связывания транскрипционных факторов. Реализация на FPGA семейства Virtex5 позволяет значительно распараллеливать операции сравнения мотивов, а также хранить во внутренней памяти кристалла входного массива данных, что позволяет значительно уменьшить обмен данных с внешней памятью и добиться значительного роста производительности. Применение разработанного программно-аппаратного комплекса HDG позволит в 2 000 раз ускорить решение задачи по сравнению с универсальным ПК на базе процессора Core2Duo. Использование же решения на базе FPGA XC5VLX330T повысит производительность в 20 000 раз.
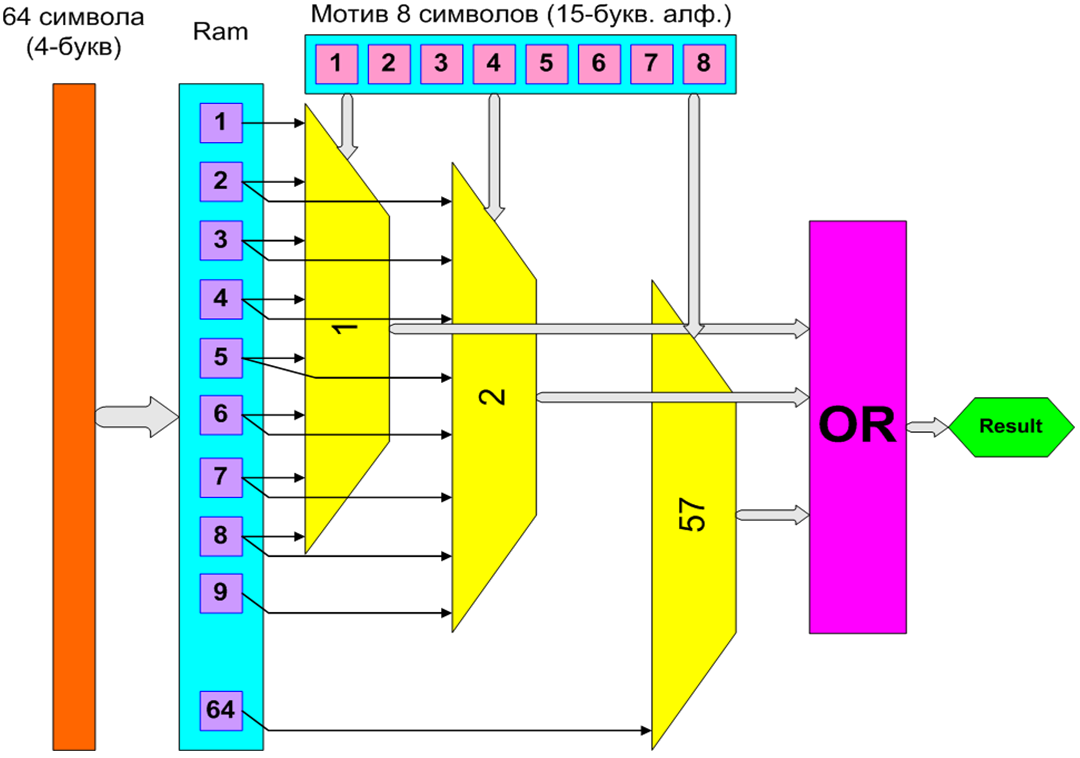
Реализация на FPGA поиска мотива в строке
|
")
")